Hessian 谱的 "Bulk + Spikes" 结构
Hessian 谱的 “Bulk + Spikes” 结构
Hessian 我们都知道,一个二阶导:
Hessian 的特征值描述了特征向量方向的曲率。正特征值对应山谷(局部极小),负特征值对于山峰,值的绝对值大小则反映了曲率。
根据 Yann Lecun 的说法,hessian非常奇异(singular),特征值大量集中在零附近,并且存在少量独立的较大的特征值。其中,将大特征值称为 Spike,将大量的零特征值称为 Bulk
并且,他还通过实验给出了一些对这一现象的直观理解:
- 增大模型参数,特征值似乎越靠近零点。这种集中可能反映了模型的过参数化冗余。
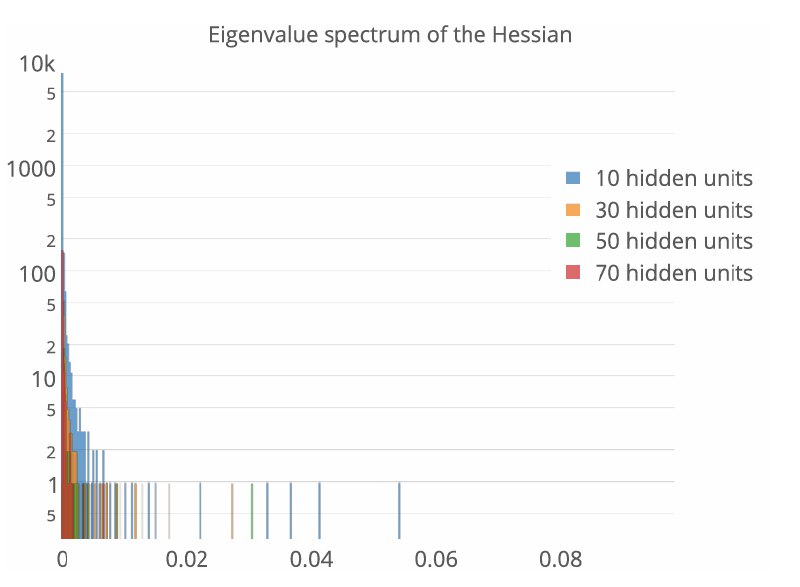
模型越大,Hessian越奇异
- 数据分布越复杂,大特征值会更极端。通常认为大特征值可能与数据本身主要结构和信息密切相关。
数据越难,Hessian的大特征值绝对数值越大(原论文的图也太糊了)
不过,这篇文章写的相当随意,就像我的博客一样,实验规模也很小。但确实是很适合我这种懒人的省流版,更详细的工作不妨参考 Hessian Eigenspectra of More Realistic Nonlinear Models 这篇。
Wigner半圆定律
Wigner半圆定律描述了一类特定的随机矩阵特征值谱的渐进分布,具体地:
$W$ 是一个 $N \times N$ 的实对称随机矩阵(Wigner矩阵),其满足以下条件:
对角线及上三角部分的元素 $W_{ij}(i\leq j)$ 是独立同分布 (i.i.d.) 的随机变量
这些随机变量的均值为零,即 $\mathcal{E}[W_{ij}]=0$
方差为 $\sigma^2$,即 $\mathcal{E}[W_{ij}^2]=\sigma^2$
结论是,当矩阵维度 $N \rightarrow \infty$ 时,矩阵 $\frac{1}{\sqrt{N}}W$ 的特征值的经验谱分布依概率收敛于 Wigner 半圆分布。其概率密度函数为:
这个分布的支撑集在 $[-2\sigma, 2\sigma]$ 区间内,其形状顾名思义是一个半圆形。
不过,这一理论和实际相去甚远,说明 Hessian 矩阵的结构远比一个简单的 Wigner 矩阵复杂,还依赖于数据、网络架构和损失函数等等。
Marchenko-Pastur 定律
描述的是协方差矩阵的特征值分布
令 $X$ 是一个 $M \times N$ 的随机矩阵,其元素 $X_{ij}$ 是独立同分布的随机变量,均值为0,方差为 $\sigma^2$。考虑由它构成的样本协方差矩阵 $S = \frac{1}{M}X^TX$
在 $M, N \rightarrow \infty$ 且比率 $\gamma = \frac{N}{M}$ 收敛到一个常数的极限下,矩阵 $S$ 的特征值经验谱分布依概率收敛于 Marchenko-Pastur 分布。其概率密度函数为:
分布的支撑集为 $\lambda_{±} = \sigma^2 (1 ± \sqrt{\gamma})^2$
与 Hessian 的联系
这个和 Hessian 的联系在于,我们考虑损失函数为
我们暂且将模型当成一个黑箱参数,计算 Hessian
这里包含两个部分,我们分开来看。
第二部分不需要再额外求解:
$\frac{\partial \mathcal{l}}{\partial z_k}$ 就是损失对第 $k$ 个 logit 的梯度
$\frac{\partial^2 z_k}{\partial \theta_m \partial \theta_j}$ 是第 $k$ 个 logit $z_k$ 关于参数 $\theta$ 的 Hessian 矩阵的 $(m, j)$ 元素。我们可以把它记为 $(\nabla_{\theta}^2 z_k)_{mj}$
第一部分需要再使用链式法则:
这里 $\frac{\partial \mathcal{l}}{\partial z_k}$ 对 $\theta_m$ 求导时,需要注意到 $z$ 是 $\theta$ 的函数,所以应用链式法则:
看起来有点复杂,但是:
$\frac{\partial z_s}{\partial \theta_m}$ 是雅可比矩阵 $J$ 的元素 $J_{sm}$
$\frac{\partial^2 \mathcal{l}}{\partial z_s \partial z_k}$ 是损失关于 logitis 的 Hessian 矩阵
$\frac{\partial z_k}{\partial \theta_j}$ 是雅可比矩阵 $J$ 的元素 $J_{kj}$
所以第一部分其实可以写成
综上,Hessian可以写成
其中
$J_i=\nabla_{\theta}z_i$ 是第 $i$ 个样本的 logits 关于参数 $\theta$ 的雅可比矩阵
$H_{\mathcal{l}, i} = \nabla_z^2 \nabla(z_i, y_i)$ 是损失函数 $\mathcal{l}$ 关于 logits $z_i$ 的 Hessian 矩阵。
$\frac{\partial \mathcal{l}}{\partial z_{ik}}$ 是损失对第 $k$ 个 logit 的偏导数。
$\nabla^2 z_{ik}$ 是第 $k$ 个 logit 关于参数 $\theta$ 的 Hessian
Gauss-Newton Estimation
(p.s. 谁懂这两个名字一起出现的救赎感)
接下来要说明,上式中的第二部分可以近似抛弃。
首先直观地理解,对于交叉熵损失函数而言 $\frac{\partial \mathcal{l}}{\partial z_{ik}} = p_{ik} - y_{ik}$,在模型训练后期,这一项可能很小,因此可以抛弃。
然而,还有一个更神奇的东西,叫 Fisher 信息矩阵(FIM),一个定义是真实 Hessian $H$ 在模型自身预测的概率分布下的期望值。也就是说,我们假设真实标签 $y_i$ 是从模型自己的输出分布 $p(y|x_i ; \theta)$ 中采样得到的。
我们来计算第二部分在这个期望下的值。我们知道 $\nabla^2 z_{ik}$ 并不依赖于标签 $y_i$,因此
最关键的一步是,因为我们假设 $y_i$ 是从模型的概率分布 $p_i$ 中采的,所以 $y_{ik}$ 取值为1的概率是 $p_{ik}$,因此 $\mathbb{E}[p_{ik} - y_{ik}] = 0$
我们将第一部分称为 广义高斯-牛顿项 (GGN),它的期望就等于 FIM。也就是说,近似操作本身不是无脑省略,而是得到了一个非常有意义的 FIM(我甚至觉得,它比 Hessian 更好)
广义高斯牛顿项与协方差矩阵
扯远了,回到 Marchenko-Pastur 定律,接下来证明广义高斯牛顿项 $J^TH_{\mathcal{l}}J$ 就可以看成是一种协方差矩阵
对于交叉熵损失函数:
$\frac{\partial \mathcal{l}}{\partial z_k} = p_k - y_k$
$(H_{\mathcal{l}})_{kj} = \frac{\partial^2 \mathcal{l}}{\partial z_k \partial z_j} = \frac{\partial p_k}{\partial z_j} = \frac{\partial \text{softmax}(z)_k}{\partial z_j} = p_k(\delta_{kj}-p_j)$
因此,我们有:
也就是说,$H_{\mathcal{l}}$ 可以视作一个均值为 $p$ 的 one-hot 向量 $y$ 的协方差矩阵,因为
作为一个协方差矩阵,$H_{\mathcal{l}}$ 是半正定的。又因为它本身是对称的,因此必然存在一个矩阵 $H_{\mathcal{l}}^{\frac{1}{2}}$,使得
所以,对于我们的GGN项,可以把 $H$ 分解掉
因此,我们唯一需要做的近似就是,$\tilde{J} = H_{\mathcal{l}}^{\frac{1}{2}}J$ 是一个随机变量,由它构成的协方差矩阵 $G$ 的特征谱密度自然应该遵循 Marchenko-Pastur 定律。
总结
总的来说,Marchenko-Pastur 的解释能力要强得多,这从推导就能看得出来。
参数 $\gamma = \frac{N}{M}$ 通常远小于1,$N$ 是批次大小(因为 $\tilde{J}^TH_{\mathcal{l}}\tilde{J}$ 是 $\sum_{i=1}^n [J_i^T H_{\mathcal{l}, i}J_i]$ 堆叠起来的,不要忘了),$M$ 是参数维度。这也能解释 Yann Lecun 的实验结果:参数维度越大,$\gamma$ 就越小,支撑集就越小,所以 bulk 就越紧凑
更进一步,如果真实的协方差矩阵是一个低秩矩阵(信号)加上一个随机矩阵(噪声),那么其样本协方差矩阵的特征值谱就会呈现一个 MP 分布的 Bulk 和脱离 Bulk 的刺,与实验观察到的结果一致。







