Part I of Mathematical Structure of Mamba - Hippo
本篇是mamba系列blog的第一篇文章
Part I of Mathematical Structure of Mamba - Hippo
剩余预计还有一篇文章正在生产中~
序言
考虑一个很长的一维序列,当我们希望模型具有“记忆”能力的时候,我们实际上期望模型能在当前时间步对很久以前的时间步上的数据点具有无损恢复的能力。然而,模型的大小是不可能随序列长度增长的,也就是说我们需要使用有限的参数恢复出无限多时间步的数据点。
很显然无损恢复是不可能的。但是,我们可以用一种具有渐进收敛性的方法,尽可能减少这种损失。我们面临的第一个问题就是,怎样描述这个损失?一个非常自然的想法是直接把我们恢复出来的数据点和真实的数据点的距离求 $L_2$ 范数。Naive的 $L_2$ 范数假设了所有历史数据点是同等重要的。
到这里,我们起码有了一种最简单的求损失的方法。如果我们把所有真实数据点看作对时间步的函数,那么我们上面求损失的过程正是函数逼近的过程,即我们不知道真实函数的表达式,但我们获取了它的若干采样数据点,我们可以依赖这些数据点,选取一个已知表达式的函数来逼近它。这个用于逼近的函数包含有限多的待优化的参数,而参数的数量不随序列长度变化。
记忆问题转化为了函数逼近问题
数学框架
考虑定义在 $t>0$ 上的一维连续函数 $f(t)\in \mathbb{R}$,则 $t$ 时刻之前的历史可以表述为
对于每个 $t$ 时刻,我们希望找到一个已知表达式的函数 $g^{(t)}\in \text{span\{}\mathcal{G}\}$ 来逼近历史 $f_{\leq t}$,其中 $\mathcal{G}$ 是我们所有可选择函数构成的函数族。
在给定概率测度 $M^{(t)}$ ,对应概率密度 $\mu$ 满足 $\int_{-\infty}^{t}\mu^{(t)}(x)\text{d}x = 1$ 的情况下,两个函数的内积可以表示为:
同时,带概率测度的 $L_2$ 范数变为
要进行函数逼近,我们首先要选取一组基函数来构建函数族。最常见的选择是使用多项式基,来对概率测度 $M^{(t)}$ 构建一组 正交多项式 $\mathcal{G}=\{g_n\}_{n<N}$,满足 $\forall i,j \in [N], \langle g_i, g_j \rangle _{\mu^{(t)}}=\int_0^{\infty}g_i(x)g_j(x)\mu^{(t)}(x)\text{d}x=0$,来找到一个 $g^{(t)}=\sum_{k=0}^{N-1}c_k(t)g_k$ 去最小化在测度 $M^{(t)}$ 下与 f(t) 之间的损失,即:
对于上式, $f_{\leq t}$ 可以直接观测得到,$\mathcal{G}$ 可以通过构造得到(勒让德多项式、切比雪夫多项式、雅可比多项式等等),$\mu^{(t)}$可以直接设定(例如设定为所有历史同等重要,或只关注此时刻往前固定窗口大小的历史),那么我们唯一要优化的就是一组系数 $[c_k(t)]_{k\in[N]} \in \mathbb{R}^{N}$
后文中介绍了如何在测度加权的情况下推导出正交多项式
在某一时刻 $t$ 的一组参数 $c_k(t)$ ,我们可以简单通过最小二乘法求得
对 $c_i$ 求导,令导数为0
由于 $\int g_k^{(t)}(x)g_i^{(t)}(x)\mu^{(t)}(x)\text{d}x=1$ 当且仅当 $k=i$,所以
也即 $c_i(t)=\langle f_{\leq t}, g_i^{(t)} \rangle_M = \int f_{\leq t}(x)g_i^{(t)}(x)\mu^{(t)}(x)\text{d}x$
数学上,我们可以简单计算得到。但考虑时间复杂度,每次计算都需要遍历所有的历史求出 $f_{\leq t}$,$n$ 次操作的总复杂度依然是 $O(n^2)$ ,无法接受。
可以看到 $c(t)$ 是关于时间 $t$ 的函数,考虑到相比上个时刻 $T-\delta$ 仅有一个增量数据点 $f(T)$,自然考虑 $c(t)$ 的求解是否存在递推形式,也即关注 $c(t-\delta)$,$c(t)$,$f_{\leq t}$ 三者之间的关系。在连续情况下当 $\delta \rightarrow 0$ 时,我们关心的是 $\frac{d}{dt}c(t)$,$c(t)$,$f_{\leq t}$ 三者之间的关系,也就是求解一个关于 $c(t)$ 的常微分方程(ODE):
数学推导
根据前面的数学框架,我们需要找到一组正交多项式 $\{g_n\}_{n<N}$ 和测度 $M^{(t)}$,并求解常微分方程 $\frac{d}{dt}c(t)=u(t, c(t), f_{\leq t})$。选取不同的多项式和测度,我们会得到不同的ODE方程和解,此处仅介绍 HiPPO 框架中最成功的一种变体:HiPPO-LegS(Scaled Legendre,LegS),它使用勒让德多项式作为正交多项式,并选取均匀重要性的测度。
概率测度

HiPPO论文中提出的三种概率测度,从左往右分别为:LegT(将滑动窗口内的历史视为同等重要)、LagT(历史的重要性指数衰减)、LegS(将所有历史视为同等重要)
在某个时刻 $t$,将此前的所有历史视为同等重要,我们得到HiPPO-LegS的测度:
或者写成:
因为这个测度实际上是 $x$ 的函数
正交多项式
为了获得正交多项式,一般的做法是对一组函数进行Gram-Schmidt正交化。当我们对 $1, x, x^2, \cdots$ 进行正交化后,得到的就是勒让德多项式:$P_0(x), P_1(x), P_2(x), \cdots$。
标准勒让德多项式有一个性质,我们不加证明地给出:在区间 $[-1,1]$ 上,两个多项式 $P_n, P_m$ 具有以下关系:
$\delta_{nm}$ 表示当 $n \neq m$ 时等于 0,因为正交嘛;当 $n=m$ 时等于1
由于该性质定义在区间 $[-1,1]$ 上,我们进行变量代换 $x=\frac{2x’}{t}-1$ 放缩到我们关心的 $[0,t]$ 区间,代换后的公式为:
两个多项式在区间 $[0,t]$ 上积分等价于在给定测度 $\mu^{(t)}(x)=\frac{1_{[0,t]}}{t}$ 下在整个数轴上的积分,上式写为:
我们仅考虑 $n = m$ 的情况:
令 $g_n^{(t)}(x)=(2n+1)^{\frac{1}{2}}P_n(\frac{2x}{t}-1)$,我们有:
所以,在测度 $M^{(t)}$ 下归一化的勒让德正交多项式为:
怎么证明当 $n \neq m$ 时有 $\int g_n^{(t)}(x) g_m^{(t)}(x) \mu^{(t)}(x) \text{d}x = 0$ ?
常微分方程
要计算 $\frac{d}{dt}c(t)$, 我们需要对 $c(t) \in \mathbb{R}^N$ 的每一维 $c_n(t)$ 求导。根据 $c_n(t):=\langle f_{\leq t}, g_n^{(t)} \rangle_{\mu^{(t)}}$,同时我们希望避免对 $f_{\leq t}$ 进行计算,那么可以借助计算 $\frac{d}{dt}g_n^{(t)}$ 和 $\frac{d}{dt}\mu^{(t)}$ 得到(看了后面推导就知道为什么了)。
在此前的推导中,我们将 $t$ 视为一个固定的时刻而非变量,因此 $t$ 作为上标出现。而在接下来的ODE推导中,时间 $t$ 也是变量,因此下面的记号改为类似 $g(t, x)$,$\mu(t,x)$ 的形式。
$f_{\leq t}$ 是一个已经确定的函数,代表的是我们看到的采样点背后的真实逻辑,并不是 $t$ 的函数。
可以理解为,$f_{\leq t}$ 是通过 $f(1), …, f(t)$ 拟合出来的一个函数,求出这个函数的复杂度是 $O(t)$
补充一下勒让德多项式的递推关系式 $(2n+1)P_n=P_{n+1}’-P_{n-1}’$,以及推论 $(x+1)P_n’(x)=nP_n(x) + (2n-1)P_{n-1}(x) + (2n-3)P_{n-2}(x) + \cdots$,下面是勒让德多项式的表,可以自己验证一下。

标准勒让德多项式
对于 $\frac{\partial}{\partial t}\mu(t,x)$,我们有:
对于 $\frac{\partial}{\partial t}g_n(t,x)$,我们有:
进行变量代换 $z=\frac{2x}{t}-1$ 简化公式,并使用勒让德多项式的推论可以得到:
然后,我们可以来计算 $\frac{d}{dt}c_n(t)$
代入 $\frac{\partial}{\partial t}g_n(t,x)$,$\frac{d}{dt}\mu(t,x)$ 的计算结果,可以得到:
其中 $g_n(t,t) = (2n+1)^{\frac{1}{2}}P_n(1)=(2n+1)^{\frac{1}{2}}$,代入得到:
至此,我们完成了推导,并实现了初始目标,将 $\frac{d}{dt}c(t)$ 表示为了 $c(t)$ 与 $f_{\leq t}$ 的函数,且不依赖对观测函数 $f_{\leq t}$ 的积分,避免了对所有历史的计算。有了 $\frac{d}{dt}c_n(t)$ 的表达式,我们可以将向量 $c(t)$ 表示为矩阵计算形式:
这里的矩阵 $A$ 就是大名鼎鼎的HiPPO Matrix,S4(Structured State SpaceS)中“结构化”指的就是用结构化的矩阵 $A$ 来对 SSM 的参数初始化
HiPPO矩阵初始化代码
补充一下HiPPO矩阵初始化的代码,HiPPO矩阵是一个 $N \times N$ 维的下三角矩阵:
1 | def make_HiPPO(N): |
返回 $-A$ 是为了和后续的SSM状态方程对齐,把负号放到参数内部。
HiPPO 离散化
以上推导都是在假设 $f(t)$ 是关于 $t$ 的连续函数的情况下进行的。通过离散化,我们可以获得针对序列数据的离散ODE。连续函数离散化的方法有很多,例如前向欧拉、后向欧拉、双线性等等。在这里我们介绍形式相对简洁的前向欧拉方法以及离散化后的HiPPO-LegS,需要注意的是在HiPPO论文的实验以及S4中使用的都是双线性离散化方法,因为具有更好的数值稳定性,而mamba则是采用的零阶保持(zero-order hold, ZOH)方法。
已知 $\frac{d}{dt}c(t) = -\frac{1}{t}Ac(t) + \frac{1}{t}Bf(t)$ ,对于前向欧拉,假设采样间隔为 $\Delta t$,我们从时刻 $t$ 向前走一小步得到 $t+\Delta t$,对这一小段在等式两边积分得到:
对于等式右边我们将 $[t,t+\Delta t]$ 内 $\frac{d}{dt}c(t)$ 的值都保持为 $t$ 时刻的值来近似,有:
移项得到:
将 $t_k$, $t_k+\Delta t$ 时刻分别当成离散的 $k$,$k+1$ 时间步,即 $t_k=k \cdot \Delta t$,我们得到前向欧拉离散化的HiPPO-LegS:
双线性离散化就是 $c(t+\Delta t)-c(t)=\frac{\Delta t }{2}(\frac{dc(t)}{dt}+ \frac{dc(t+\Delta t)}{dt})$
在S4D部分会介绍零阶保持方法。
理论性质
HiPPO-LegS有非常多良好的性质,作者也都对它们进行了证明。在这里我们对大部分性质直接介绍结论,证明可以在HiPPO论文的附录E中找到。
时间尺度鲁棒性
对于某些从连续信号采样得到的离散序列数据(例如语音信号、时间序列数据),如果采样率很高,模型往往需要处理非常长的数据序列,直接使用序列模型计算量会非常大,实践中往往会用一些卷积或池化模块来降低计算量,但这样的模型在同一个连续信号、不同采样率的数据上不能直接迁移,对时间尺度敏感。HiPPO-LegS对时间尺度是鲁棒的,意味着它对不同采样率得到的序列数据可以方便地迁移。
对 $x$ 做变量代换,令 $x := \frac{x}{\alpha}$
也就是说,若对原始函数 $f$ 进行尺度变换得到 $\tilde{f}$,从 $f$ 使用 $\alpha \Delta t$ 采样等价于使用 $\Delta t$ 从 $\tilde{f}$ 进行采样,得到的 HiPPO 系数也仅仅发生了尺度变化,$\tilde{c}_2 = c_1, \tilde{c}_4 = c_2, \cdots$。这样的性质可以保证 HiPPO 对于数据序列 $f_1, f_2, \cdots, f_4$ 和 $\tilde{f}_1, \tilde{f}_2, \cdots, \tilde{f}_8$ 的输出完全一致:$c_4 = \tilde{c}_8$,我们可以随时迁移不同的采样率进行训练/测试。
梯度良好
长久以来困扰序列模型的一大问题就是梯度消失问题,即某个时间步的梯度往相邻较远的时间步回传的时候,梯度的模会随着距离指数下降。HiPPO-LegS可以保证系数之间的敏感性/梯度随着序列长度线性下降,从而很大程度缓解梯度消失的问题。
对任意两个时间步 $k<l$,HiPPO系数在第 $l+1$ 步与 $k$步 之间的梯度的模收敛于 $1/l$:
误差逼近收敛快
前面提到,对于有限长度的HiPPO系数,我们不可能完美恢复出(可能)无限长的原始信号 $f$ 。但 HiPPO 恢复出来的函数 $g^{(t)}$ 与历史 $f_{<t}$ 之间的误差可以随着系数维度的增加快速收敛。在实践中,使用64维的系数已经能非常好地逼近数十万step的原始数据。假设 $f$ 有 $k$ 阶导数,并且第 $k$ 阶导数是有界的,那么逼近误差的收敛速度可以表示为:
可以看到误差收敛和系数维度 $N$ 以及函数 $f$ 的光滑程度 $k$ 都有关,对于大部分比较光滑的函数,$k$ 值比较大,随着 $N$ 的增加逼近误差会快速减少。
模型
本文提出的基于HiPPO的模型非常简单,就是在常规的Gated RNN中门控单元里加入了HiPPO系数作为额外的信号:
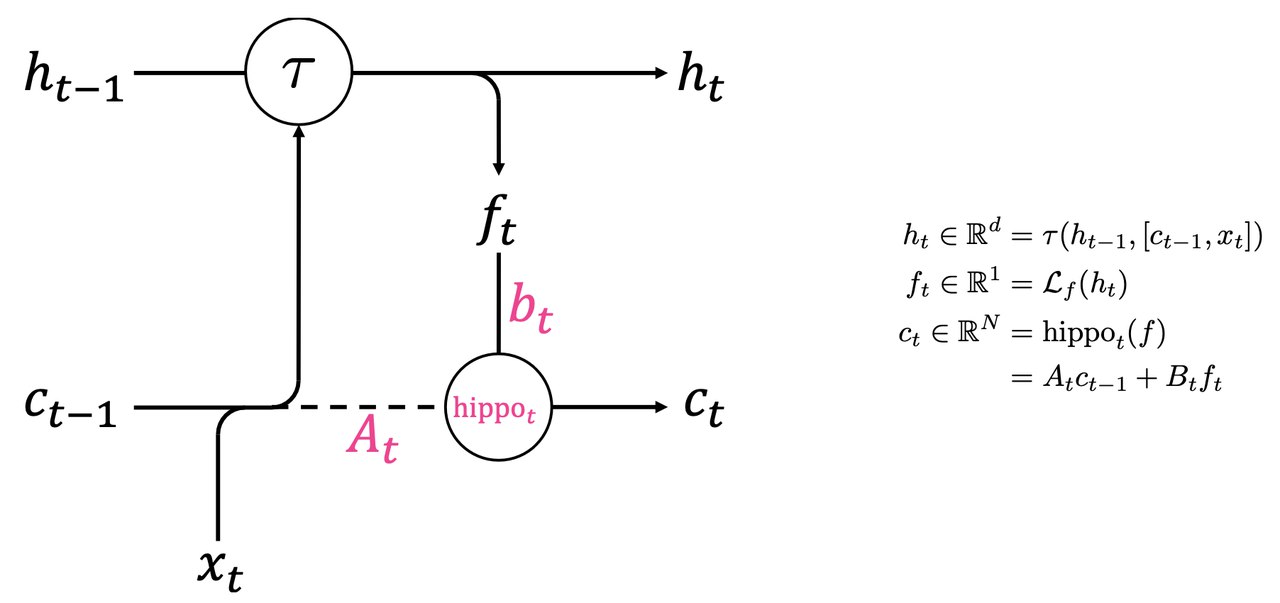
基于HiPPO的序列模型
其中 $\mathcal{L}_f$ 为一个线性层,将 $N$ 维embedding投影到一维;$\tau$ 为任意的RNN更新函数,可以是多层的神经网络;$A_t, B_t$ 是将时间/步长相关的变量放到原始 HiPPO Matrix 里,这里是为了简化表示,例如对于前向欧拉离散化的 HiPPO-LegS 有 $A_t = 1 - \frac{A}{t}$
实验
图像序列化分类
常见的图像分类都是在二维图片上分类,SOTA模型是CNN系列的卷积模型。这里考虑的任务是将MNIST图片的像素顺序打乱并拍平成一维像素序列,使用序列模型进行分类。显然,由于像素被打乱,数据的局部特征被破坏,需要在这样的序列数据上成功分类,需要模型几乎记住所有的像素,才能对它们在hidden space进行组合和变换。根据试验结果可以看到,基于HiPPO的模型不仅超过了LSTM以及各种序列模型,甚至超过了Transformer这种具有全局感受野的模型,体现出HiPPO强大的记忆能力。表中没有CNN的结果应该是因为CNN严重依赖局部特征,打乱像素后模型无法正常工作。

实验:图像序列化分类
采样率OOD的序列数据分类
在某些场景,我们需要对整条序列数据进行分类,例如脑电数据序列(EEG)等。很常见的问题是,不同医院对脑电波的采样率可能不同,在一家医院的数据上训练的模型可能无法直接迁移到另一家医院使用。HiPPO论文在这种类型的OOD问题数据集上进行了测试,训练和测试数据来自同一类信号,但采样率不同。从试验结果可以看到,HiPPO具有非常出色的采样率鲁棒性。

实验:采样率OOD的序列数据分类
随机函数逼近
最后,作者测试了对于一些随机函数,使用模型进行函数逼近的效果,即序列地在函数每个时间步运行模型,输出对历史数据的预测。可以看到LSTM几乎无法正常工作,但HiPPO对函数逼近地非常成功。

实验:随机函数逼近
Reference
组会内部分享报告 《A Gentle Introduction to HiPPO🦛 and its Friends》








